
Chi-Quadrat-Test
Es gibt mehrere Varianten des Chi-Quadrat-Tests, dieser Beitrag befasst sich mit dem Chi-Quadrat-Anpassungstest, auch Chi-Quadrat-Verteilungstest genannt.
Chi-Quadrat-Anpassungstest
Wozu ein Chi-Quadrat-Test? Was macht man damit?
Der Chi-Quadrat-Anpassungstest (oder -Verteilungstest) prüft, ob eine Stichprobe tatsächlich einer gewissen Verteilung folgt. Man kann damit beispielsweise testen, ob der Notenspiegel einer Klausur normalverteilt ist oder nicht.
Wie wird das ganz grob gemacht?
Wir haben eine Stichprobe sowie eine Nullhypothese, nämlich dass ebendiese Stichprobe einer gewissen Verteilung folgt. Ganz grob wird geschaut, wie eine Stichprobe genau aussehen müsste, wenn sie perfekt nach dieser Verteilung gezogen würde. Und dann schauen wir uns den Unterschied zwischen unserer tatsächlichen Stichprobe und der “perfekten” Stichprobe an. Wenn die beiden relativ ähnlich sind sagen wir “Ja, unsere Stichprobe folgt der Verteilung”, andernfalls eben nicht (und wir verwerfen die Nullhypothese). Der Chi-Quadrat-Test gibt uns ein genaues Maß für diese “Ähnlichkeit”, und sagt uns genau, ob die Verteilungen ähnlich genug sind, oder nicht!
Erklärung an einem Beispiel
Nehmen wir doch mal als erstes Beispiel einen Notenspiegel aus der Schule, z.B. den folgenden:
| Notenpunkte: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Häufigkeit: | 0 | 1 | 0 | 1 | 2 | 3 | 4 | 7 | 8 | 6 | 3 | 4 | 2 | 2 | 0 | 1 |
Sieht ja erstmal ziemlich normalverteilt aus, oder?
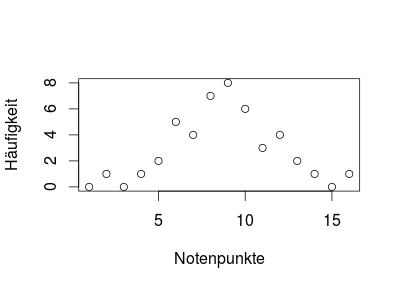
Das wollen wir jetzt überprüfen. Zunächst einmal bezeichnen wir die verschiedenen Notenpunkte auf der Skala als “Kategorien”. Das ist wichtig für einen Chi-Quadrat-Test: Unsere Stichprobe muss schon in m Kategorien eingeteilt sein. Hier ist das ja anhand der Notenpunkte schon gegeben und wir haben m=16 Kategorien, wir formulieren es aber noch etwas mathematischer: Aus der Kategrie “12 Punkte” zum Beispiel wird die Kategorie: “Punktzahl >= 12.5, aber < 13.5”. Und da eine Normalverteilung nicht nur zwischen 0 und 15 liegt, müssen wir die “Randkategorien” noch ein bisschen erweitern, sprich: aus der Kategorie “15 Punkte” wird die Kategorie “>= 14,5 Punkte” und aus “0 Punkte” wird “< 0.5 Punkte”.
Definition der Nullhypothese
Wir formulieren also zunächst die Nullhypothese. Hier gibt es einen feinen Unterschied: Wir können die Parameter der zu testenden Verteilung selbst festlegen oder aus der Stichprobe berechnen lassen. Ich gehe hier zunächst den ersten Fall durch, am Ende kommt noch ein kurzer Abschnitt über den anderen. Ich gehe jetzt davon aus, dass die Parameter, die wir schätzen wollen, schon bekannt sind. Zum Beispiel weil uns vorgegeben wurde, genau diese Werte zu testen, kann ja sein, dass der Rektor der Schule will, dass die Klausuren immer nach dieser Verteilung verteilt sind und andernfalls die Punkteskala verändert werden soll.
Die Parameter der Nullhypothese fallen also jetzt quasi ein bisschen “vom Himmel”. Die Nullhypothese lautet:
Unsere Stichprobe ist normalverteilt mit Erwartungswert μ=8 und Standardabweichung σ=3
Erzeugen der erwarteten Stichprobe
Jetzt müssen wir gucken, wie die erwartete Stichprobe einer solchen Verteilung aussieht: Wieviele Elemente würden in jede Kategorie fallen? Hierfür müssen wir zunächst für jede Kategorie die Wahrscheinlichkeiten berechnen, dass ein Element aus einer solchen Stichprobe in diese Kategorie fällt, in unserem Beispiel also sechzehn Wahrscheinlichkeiten. Die einzelnen Werte der Wahrscheinlichkeit im folgenden sind aus einer Tabelle der kumulierten Standardnormalverteilung (Normalverteilung mit Erwartungswert 0 und Standardabweichung 1) genommen. In einer solchen Tabelle stehen nämlich immer genau die Wahrscheinlichkeiten, dass ein x kleiner gleich einem bestimmten Wert ist. Innerhalb der Wahrscheinlichkeits-Terme verschiebe ich auf beiden Seiten um Erwartungswert und Standardabweichung, dann ist das Resultat nämlich standardnormalverteilt (eine ganz wichtige Eigenschaft von Normalverteilungen!), denn diese Wahrscheinlichkeiten kann ich aus einer Tabelle holen. Auch benutze ich einige Rechenregeln der Normalverteilung, z.B. dass Φ(-x) = 1-Φ(x) für jedes x gilt und dass P(Z>x) = 1-P(Z<x) = 1-Φ(x); das liegt einfach an der Symmetrie der Normalverteilung und ihr solltet euch kurz mal überlegen, dass das auch stimmt. Die Wahrscheinlichkeiten sind:
$$ \begin{align*} P(X \in C_0) &= P(X < 0.5) = P\left(\frac{X-8}{3} < \frac{0.5-8}{3}\right) = P(Z < -2.5) = \Phi(-2.5) = 1-\Phi(2.5) \\ &\approx 1-0.99379 = \underline{0.00621} \\ P(X \in C_1) &= P(X \in \left[0.5; 1.5\right)) = P(X<1.5) - P(X<0.5) \\ &= P(\frac{X-8}{3} < \frac{1.5-8}{3}) - P(\frac{X-8}{3} < \frac{0.5-8}{3}) = P(Z < -2.17) - P(Z < -2.5) \\ &= [1-\Phi(2.17)] - [1-\Phi(2.5)] = \Phi(2.5) - \Phi(2.17) \approx 0.99379 - 0.98500 = \underline{0.00879}\\ P(X \in C_2) &= P(X \in \left[1.5; 2.5\right)) = P(X<2.5) - P(X<1.5) \\ &= P(\frac{X-8}{3} < \frac{2.5-8}{3}) - P(\frac{X-8}{3} < \frac{1.5-8}{3}) = P(Z < -1.83) - P(Z < -2.17) \\ &= [1-\Phi(1.83)] - [1-\Phi(2.17)] = \Phi(2.17) - \Phi(1.83) \approx 0.98500 - 0.96638 = \underline{0.01862}\\ P(X \in C_3) &\approx \underline{0.03319}\\ P(X \in C_4) &\approx \underline{0.05419}\\ P(X \in C_5) &\approx \underline{0.08227}\\ P(X \in C_6) &\approx \underline{0.10527}\\ P(X \in C_7) &\approx \underline{0.12397}\\ P(X \in C_8) &\approx \underline{0.13498}\\ P(X \in C_9) &\approx \underline{0.12397}\\ P(X \in C_{10}) &\approx \underline{0.10527}\\ P(X \in C_{11}) &\approx \underline{0.08227}\\ P(X \in C_{12}) &\approx \underline{0.05419}\\ P(X \in C_{13}) &\approx \underline{0.03319}\\ P(X \in C_{14}) &\approx \underline{0.01862}\\ P(X \in C_{15}) &= P(X \geq 14.5) = P\left(\frac{X-8}{3} \geq \frac{14.5-8}{3}\right) = P(Z \geq \frac{6.5}{3}) = 1-\Phi(2.17) \\ &\approx 1-0.985 = \underline{0.015} \end{align*} $$
Man kann kurz überprüfen, ob man alles richtig gemacht hat, indem man alle Wahrscheinlichkeiten aufaddiert. Da muss 1 raus kommen, abgesehen von kleinen Rundungsfehlern. Aus den Wahrscheinlichkeiten können wir nun die zu erwartende Stichprobe bauen. Unsere Ausgangsstichprobe hatte ja 44 Schüler. Wir schauen nun, wie eine Notenverteilung von 44 Schülern aussehen würde, wenn sie perfekt normalverteilt mit Parametern μ=8 und σ=3 wäre. Hierfür müssen wir einfach für jede Kategorie die Wahrscheinlichkeit der Kategorie mit 44 malnehmen. Denn die Wahrscheinlichkeit sagt uns ja, wie wahrscheinlich es ist, dass ein Element in die Kategorie fällt. Nun haben wir also 44 Elemente und für jedes dieselbe Wahrscheinlichkeit. Unsere erwartete Stichprobe sähe also so aus:
| Notenpunkte: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Häufigkeit: | 0.2728 | 0.4048 | 0.81928 | 1.46036 | 2.38436 | 3.61988 | 4.63188 | 5.45468 |
| Notenpunkte: | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Häufigkeit | 5.93912 | 5.45468 | 4.63188 | 3.61988 | 2.38436 | 1.46036 | 0.81928 | 0.66 |
Berechnen des Abstands der erwarteten Stichprobe und der tatsächlichen Stichprobe
Wir müssen nun irgendwie ausrechnen, ob unser Notenspiegel nah an der perfekten Stichprobe dran ist oder nicht. Hier gibt es natürlich viele verschiedene Möglichkeiten, wir könnten einfach die Abstände aufsummieren und schauen, wie groß die Zahl ist, aber das ist irgendwie schwammig und nicht gerade wissenschaftlich, hieraus eine Schlussfolgerung zu ziehen. Wir brauchen ein besseres Maß! Schlaue Leute haben nun folgendes entdeckt: Wenn wir folgenden Wert als Abstandsmaß benutzen, können wir sehr mathematische Schlussfolgerungen treffen. \(\chi = \sum_{k=0}^m \frac{(N_k - n_{k0})^2}{n_{k0}}\) Dieser Wert ist nämlich chi-quadrat-verteilt mit Parameter(“Freiheitsgraden”) m-1 (Anzahl der Kategorien - 1)! Rechnen wir das ganze für unser Beispiel durch, erhalten wir den Wert
\[\chi = 5,4448\]Was können wir aus diesem Abstand folgern?
Hier kommt der eigentliche Knackpunkt des Tests: Wenn unsere Stichprobe normalverteilt war, dann muss unser χ auch chi-quadrat-verteilt sein mit Parameter m-1. Das heißt, wir können statistisch sagen, wie wahrscheinlich es ist, dass unser χ zu einer Chi-Quadrat-Verteilung passt! In unserem Beispiel müsste es also eine Chi-Quadrat-Verteilung mit Parameter 15 sein, deren Verteilungsfunktion so aussieht:
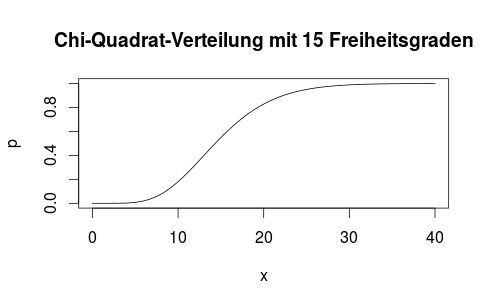
Anhand dieser Verteilungsfunktion können wir sehen, ob unser χ-Wert plausibel ist oder nicht: Diese Funktion sagt nämlich für jeden Wert x, wie wahrscheinlich es ist, dass eine chi-quadrat-verteilte Zufallsvariable einen Wert annimmt, der kleiner oder gleich diesem x ist.
Signifikanzniveau und Fehler 1. Art
Bei einem statistischen Test haben wir immer ein Signifikanzniveau gegeben. Dieses wird mit α bezeichnet und beträgt in den meisten Fällen 0,05, also 5%. Es bedeutet, dass unser statistischer Test höchstens in 5% der Fälle einen Fehler erster Art hervorbringen darf, also eine Nullhypothese fälschlicherweise verworfen wird und damit eine tatsächlich normalverteilte Stichprobe nicht als solche erkannt wird. Wichtig: Dies sagt absolut nichts über die Wahrscheinlichkeit eines Fehlers 2. Art aus, also dass eine nicht-normalverteilte Stichprobe fälschlicherweise als normalverteilt angenommen wird. Das einzige, was wir sicher sagen können: Je kleiner unser α, desto eher akzeptieren wir die Nullhypothese. Das schließt natürlich auch den Fall mit ein, die Nullhypothese fälschlicherweise zu akzeptieren! Je mehr wir uns also gegen einen Fehler 1. Art absichern, umso mehr riskieren wir einen Fehler 2. Art. In der Praxis erweist sich α=0.05 als guter Kompromiss. Um zu schauen, ob wir die Nullhypothese nun akzeptieren oder verwerfen, müssen wir schauen, für welchen Wert x einer χ²-Verteilung mit 15 Freiheitsgraden 95% aller Werte links von ebendiesem x-Wert liegen. Diesen x-Wert können wir aus einer Tabelle lesen und er beträgt x=25,00. Dies passt auch zur Verteilungsfunktion oben: Bei diesem Wert hat die Verteilungsfunktion einen y-Wert von 0,95!
Ergebnis des Chi-Quadrat-Tests
Da unser ausgerechneter χ-Wert 5,4448 unter diesem x-Wert liegt, ist es höchstwahrscheinlich, dass der χ-Wert einer χ²-Verteilung entspringt, daraus folgt, dass die Stichprobe, aus der wir den χ-Wert bestimmt hatten, tatsächlich normalverteilt war. Das heißt:
Bei einem Signifikanzniveau von α=5% verwerfen wir die Nullhypothese nicht. Wir sagen also: Ja, die Stichprobe ist in der Tat normalverteilt mit mit Erwartungswert μ=8 und Standardabweichung σ=3
Ein Beispiel wo der Chi-Quadrat-Test die Nullhypothese verwirft
Wie siehts nun aus, wenn man mal eine Stichprobe nimmt, die überhaupt nicht normalverteilt ist? Nehmen wir zum Beispiel die folgende:
| Notenpunkte: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Häufigkeit: | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
Eine Klasse mit 32 Schülern also, wo immer zwei dieselben Notenpunkte haben. Offenbar nicht normalverteilt. Wir führen den Test trotzdem durch, mit derselben Nullhypothese wie oben, also
Die Stichprobe ist normalverteilt mit Erwartungswert μ=8 und Standardabweichung σ=3
Die erwartete Stichprobe ist immernoch dieselbe, denn die hängt ja nur von der Nullhypothese ab. Bei der Berechnung von χ allerdings ändert sich etwas, schließlich haben wir nun andere Häufigkeiten in den Kategorien. Wenn man es mal durchrechnet kommen wir auf \(χ=44,0405\) Dieser Wert liegt über dem kritischen x-Wert von 25,00 (siehe oben), wir verwerfen die Nullhypothese also! Das ist ja auch gut so. Wenn wir unser α jetzt statt 0,05 auf 0,01 setzen, wir also die Wahrscheinlichkeit eines Fehlers 1. Art verringern, erhöhen wir die Wahrscheinlichkeit eines Fehlers 2. Art, dass also eine nicht-normalverteilte Stichprobe fälschlicherweise normalverteilt genannt wird, was hier passieren könnte. Was ist nun der kritische Wert? Wir schauen wieder in der Tabelle, diesmal unter den Parameter 0,99 und 15 (Freiheitsgrade) und kommen auf x=30,58. Unser berechneter Wert χ=44,0405 liegt auch darüber, d.h. auch für dieses α verwerfen wir die Nullhypothese. Wir sehen aber, dass es schon ein bisschen knapper ist. Ihr könnt euch vorstellen, dass wenn wir jetzt eine Stichprobe hätten, die noch ein paar mehr Schüler mit 8 oder 9 Punkten hätten, der Abstand zur erwarteten Stichprobe also etwas kleiner würde, wir unter Umständen unterschiedliche Ergebnisse bei unterschiedlichen Werten für α erhalten würden. Beispiel: Für die folgende Stichprobe bekommen wir unterschiedliche Ergebnisse (Nullhypothese verwerfen bzw. akteptieren) für α=0,05 und α=0,01, könnt ihr ja einmal durchrechnen:
| Notenpunkte: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Häufigkeit: | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 6 | 6 | 6 | 2 | 2 | 2 | 2 | 2 | 2 |